New: Academic Computing Drop-in Sessions
Academic computing drop-in sessions are now run by members of our team on Wednesday afternoons! Head to our drop-in info page for details & schedule....
 Legacy Storage
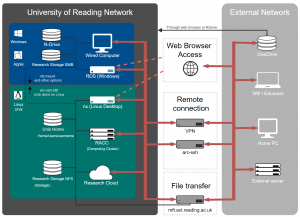
Legacy StorageThere are two shared legacy research data storage systems, the NetApp “MetCloud” storage and the Red Hat Storage cluster. Each group/project is allocated space according to it’s contribution to the system. The capacity allocated to a group/project can easily be increased as funding allows. Most research data is now being stored on the Red Hat Storage cluster, but the NetApp is still used for small volumes, and for applications where advanced storage features such as snapshotting and deduplication are beneficial.
Note that the storage volumes cannot be accessed from the head node on the cluster, you’ll need to access an interactive node to see them.
It is important not to use your home directories for storing the input and output of your jobs on the cluster, as those storage platforms are not designed to cope with this type of use. Please move all your data to a research group server or storage volume before you want to process it on the cluster.
Access to the NetApp volumes from the met-cluster nodes is via the following path:
/export/cloud/project_name
On the NetApp system you can easily recover files if you accidentally delete them. The NetApp storage keeps snapshots of the filesystem, storing 6 hourly, 2 daily, and 2 weekly snapshots. To access these change to the root directory in your groups partition, where the ‘.snapshot’ directory is located. For example, if you are in the rossby group, your group’s root directory would be ‘/export/cloud/rossby’. The ‘.snapshot’ directory doesn’t show up when you type ‘ls’ (or ‘ls -a‘). Just type ‘cd .snapshot’ to get in. To retrieve your files, you can navigate into one of the hourly, daily or weekly snapshot directories, which contain the contents of the project root directory at the snapshot time.
The RedHat Storage Cluster allows files to be spread across multiple servers so files in the same directory maybe on different servers. Also each files is copied to two different servers so that if one server fails the data is still stored on the other server.
On the met-cluster nodes (except the head node) the files from the Storage Cluster can be accessed under
/glusterfs/{volume}
Where ‘{volume}’ is the name of a project, msc or phd. Where possible this will talk directly to one (read) or both (write) of the servers in the cluster that holds the file. So traffic for different files in the same ‘{volume}’ will be spread across the cluster. If that is not possible it will talk to the server in the cluster that has been nominated to handle that ‘{volume}’ and it will talk to other the server(s).
a) Students
Access to the student Red Hat storage volumes from the met cluster nodes (or any other Linux system) is via the following path:
/glusterfs/
There are two extensible, shared volumes on the Red Hat Storage cluster, one called msc for M.Sc. students and one called phd for PhD students. There are no user quotas on any of the storage volumes – it’s up to the members of the project or users of the student volumes to use the storage sensibly.
The following conditions are attached to the use of these volumes.
– msc volume: Data will only be retained for the duration of a student’s project. All data in the volume will be deleted every year, around December to allow time for any corrections and for data to be removed. A general warning will be given first. If the data is required beyond that time it must be moved to a research grant funded volume.
– phd volume: This volume can only be used by students whose supervisors do not have access to enough research grant funded storage. Registration of user details is required before students can access the volume. Whenever possible, PhD student supervisors must use their own research grant funded storage for storing their students’ data.
b) Projects
Most project volumes can be accessed via
/glusterfs/project_name
There are some separately mounted volumes and project directories, namely:
– /net/glusterfs_atmos, which contains atmos
– /net/glusterfs_nemo, which contains nemo2 and
– /net/glusterfs_odin, which contains earth, land, marine and odin
a) Windows
To map a storage cluster volume as a network drive in Windows, you can use the OpenTextNFS Solo software.
b) MacOS X
Start by select “Connect to Server” from the “Go” menu in Finder. The path format is
smb://dfs.rdg.ac.uk/research-NFS/shared/glusterfs/VOLUMENAME
Use your university username and password.
c) Sharing data with other institutes
The storage volumes can be accessed via SSH from outside the university by connecting to hydra.nerc-essc.ac.uk. All users connecting to hydra must have a Reading University account. Guest accounts for external collaborators can be applied for using IT’s Self Service Desk, which can be found via the IT home page. Users wishing to connect to hydra from outside the university must first provide the IP address of the host or network from which they will be connecting.
In some particular cases I/O performance might be improved by using the temporary data storage located on a hard drive partition on the compute nodes. The local storage is mounted on /local on each compute node. You should treat /local as a temporary storage available only for the jobs running on the node you are using and you should remove your files from /local after your job finishes. The contents of /local might be automatically removed at bootup or when the node crashes, so you should only put files there which you are prepared to lose.
Everybody has write permissions on /local with the ‘sticky bit’ set, which means that everybody can create a directory but other users will not be able to delete it (similar to the standard /tmp directory on Linux). If you create a directory on /local, please name it identical to your user name to avoid confusion and make sure you remove it when the job finishes. If you want to have your directory created automatically on all the compute nodes, please contact it@reading.ac.uk. Please do not use the /tmp directory for research data.