New: Academic Computing Drop-in Sessions
Academic computing drop-in sessions are now run by members of our team on Wednesday afternoons! Head to our drop-in info page for details & schedule....
 RACC2 – Introduction
RACC2 – IntroductionThe new Reading Academic Computing Cluster (RACC2) is now available for use. Users are encouraged to log in and make use of the new facilities. Interactive computing and batch jobs work in the same way as on the RACC and experienced users will find that migrating to RACC2 should be straightforward.
Currently, the RACC2 documentation is in progress. In cases of missing software and libraries or if you notice problems with interactive computing or batch jobs, please let us know by raising a ticket to DTS.
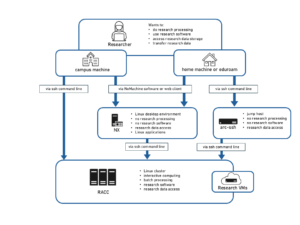
The Reading Academic Computing Cluster (RACC2) is a Linux cluster which provides resources for interactive research computing and batch job submissions for staff and students of the University of Reading. It supersedes the RACC, which is now a legacy service and not open for new users anymore. Existing RACC users are encouraged to migrate at their earliest convenience.
Most of the cluster resources are available for free for all members of the University of Reading, some additional nodes are funded and used by research projects, a service which can be requested via the Self Service Portal.
RACC2 Quick Links: |
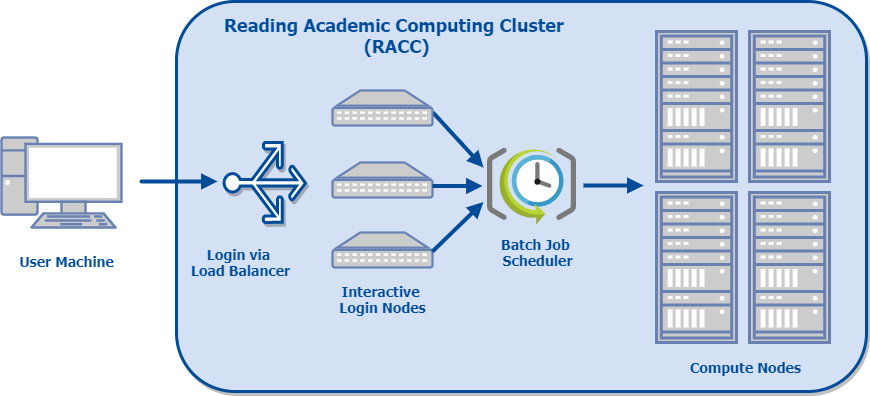
The cluster consists of several login nodes and a larger number of compute nodes. On a typical cluster, login nodes are only used for preparing and submitting batch jobs. On the RACC2 however, we provide several load-balanced login nodes equipped with multi-core processors, large memory and a fast network connection to the research data storage volumes, so that they can also be used for interactive research computing, such as data analysis and visualization, or code development and testing. Examples of software packages commonly used on the interactive nodes are Python, Matlab, R, IDL and Stata amongst other research software. If more resources are required, processing tasks can be submitted as batch jobs.
In batch mode the tasks are described in a script and submitted to the job scheduler to be run on one of the compute nodes without further user intervention. Batch job can be serial, i.e. one execution thread on one CPU core, or parallel, i.e. using many CPU cores to run multiple threads or processes on CPUs allocated on the same node, or on multiple compute nodes. Submitted batch jobs are queued and scheduled to execute on the compute nodes according to scheduling policies, taking into account request priority, the user’s current and historical resource usage, job size and resource availability.
The compute nodes provide 2048 CPU cores for serial and parallel batch jobs. Each node has 64 CPU cores and 512 GB of RAM memory. The default time limit for a batch job is 24 hours, but when it is justified, running longer batch jobs is also possible. When justified by the project requirements, it is also possible to use a compute node allocation for interactive processing.
Typically users rely on home directories for small storage needs and on chargeable Research Data Storage volumes for large storage requirements. There is also around 100 TB of scratch space, which is available for free but access is provided on request via the DTS self service portal.
This diagram shows a schematic layout of the cluster:
| Number of login nodes | 4 |
| Login node specs | 64 CPU cores, 512 GB of RAM |
| Number of compute nodes | 32 |
| Number of cores per node | 64 |
| Total number of CPU cores | 2048 |
| Memory per core | 8 GB |
| Scratch space | 100 TB |