Current Projects:
Homing task:
There are two competing theories on how we navigate. One depends on Cartesian coordinates and suggest we build a 3D reconstruction map. The other suggests we use a view-based strategy where we try to match what we see with a previously seen image. Our lab has previously provided evidence in favor of the view-based strategy. Dr Gootjes-Dreesbach and Dr Pickup implement a homing task in immersive virtual reality where participants had to find their previous location in relation to three long, thin, vertical poles. Results from this task showed that view-based model outperforms the reconstruction-based model; check out the paper here! Previous results from Dr Pickup’s experiments were also in favor of the view-based strategy; you can read a short description on our page or the paper here.
But what happens if people are in a situation that is impossible to do an image-mathcing? We created a task where participants navigate a naturalistic indoor scene in immersive VR. In order to prevent them from using an image-matching strategy we restrict their field of view (90º cone) and allow only one viewing direction permitted (e.g. North). When navigating back to their original locations, the viewing direction is now rotated by 0, 90 or 180º. You can check an example of a trial below and some preliminary data here.
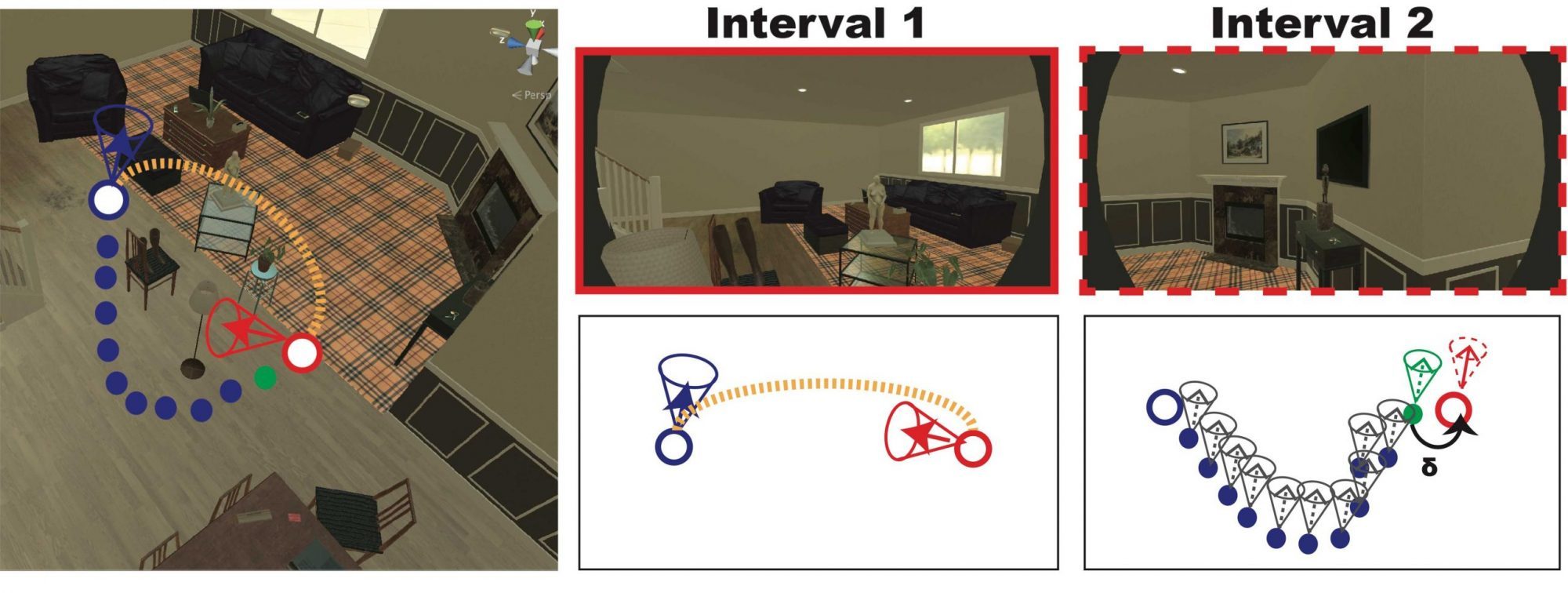
Past Projects:
Spatial Updating
How do people update the direction of objects as they move? We tested this in a real-world setting and in VR and found large systematic errors, repeatable across settings and across participants. Standard models of distorted spatial representation cannot account for these errors. We have found that a model based on affine distortions of the scene gave the most accurate prediction of pointing errors. This shows that participants implemented a strategy that was not based on the true geometry of space, nor on a unique distorted representation. To explore the raw data, click here.
This project was funded by Microsoft Research, Cambridge.
Videos:
Paper:
Vuong, J., Fitzgibbon, A. W., & Glennerster, A. (2019). No single, stable 3D representation can explain pointing biases in a spatial updating task. Scientific Reports, 9(1), 12578. https://doi.org/10.1038/s41598-019-48379-8
Homing in a minimal environment
View-based and Cartesian representations provide rival accounts of visual navigation in humans, and here we explore possible models for the view-based case. A visual ‘homing’ undertaken by human participants in immersive virtual reality. The distributions of end-point errors on the ground plane differed significantly in shape and extent depending on visual landmark configuration and relative goal location. A model based on simple visual cues captures important characteristics of these distributions. Augmenting visual features to include 3D elements such as stereo and motion parallax result in a set of models that describe the data accurately, demonstrating the effectiveness of a view-based approach.
Videos:
Publications:
Pickup, L.C., Fitzgibbon, A.W. & Glennerster, A. (2013). Modelling human visual navigation using multi-view scene reconstruction. Biol Cybern 107, 449–464. https://doi.org/10.1007/s00422-013-0558-2
Pickup, L. C., Fitzgibbon, A., Gilson, S., & Glennerster, A. (2011) “View-based modelling of human visual navigation errors,” 2011 IEEE 10th IVMSP Workshop: Perception and Visual Signal Analysis, Ithaca, NY, pp. 135-140, https://doi.org/10.1109/IVMSPW.2011.5970368
Sensory Calibration
Sensory cues have an unknown mapping to properties of the world we wish to estimate and interact with. Despite this fact, our sensory systems exhibit expert skill in predicting how the world works e.g. knowledge of mass, gravity and object kinematics.
Recent research from the lab has shown that sensory predictions, based on internal physical models of object kinematics, can be used to accurately calibrate visual cues to 3D surface slant. Participants played a game, somewhat akin to a 3D version the classic computer game Pong. The aim of the game was to adjust the slant of a surface online so that a moving checkerboard-textured ball would bounce off the surface and through a target hoop.
This shows how “high-level” knowledge of physical laws can be used to interpret and explain incoming sensory data.
Videos:
Paper:
Scarfe, P. and Glennerster, A. (2014). Humans use predictive kinematic models to calibrate visual cues to three-dimensional surface slant. Journal of Neuroscience, 34 (31), 10394-10401.
Cue Combination
A primary focus of the lab has been understanding how observers combine different sources of sensory information as they move naturally through their environment. Cue combination has been studied extensively with static observers, but rarely when an observer is free to move. It is this more natural situation that the lab is primarily interested in.
Perception of the world in an expanding room
A number of papers from the lab have examined peoples perception of 3D attributes when the scene around them expands or contracts. Remarkably, people do not notice anything odd is happening here, even when the expansion or contraction is dramatic e.g. a normal size room expanding to the size of a basketball court.
However, despite these surprising effects, observers judgements can be well modelled as statistically optimal decisions given the available sensory data. This has important implications for understanding how humans represent the 3D layout of a scene.
How and why does the expanding room work?
The expanding room experiment exploits the unique attributes of virtual reality equipment. Just as within the film Inception, we can create virtual, physically impossible worlds, which dynamically reconfigure as a person moves within them.
In the case of the expanding room the centre of expansion is a point half way between the eyes. This is important since it means that the retinal projection of a virtual object remains the same irrespective of its size. For example, a wall of the room may double its distance from you but will also double in size. Alternatively, the moon is 1/400th the size of the sun, but appears to be the same size in the sky. This is because the sun is approximately 400 times further away.
As an observer walks around in the real room, the virtual room expands or contracts depending on their position. When they are in the middle of the real room, the real and virtual rooms are the same size so the observer’s feet (which they cannot see) are at the same height as the virtual floor. On the left of the real room, the virtual room is half the size. On the right hand side of the real room, the virtual room has expanded to double its original size. Thus, walking from the extreme left to the extreme right of the physical room, the observer will see a four-fold expansion of the virtual room.
The key thing is, despite this massive change in scale, the pattern of light falling on the observer’s retina is similar to that experienced by an observer walking through a static room, although the relationship between distance walked and image change is altered. Only stereopsis and motion parallax can give the observer any clue as to the size of the room they occupy.
These are demonstrably powerful cues under normal circumstances and contribute to our ability to grasp different sized coffee mugs, navigate across furniture filled rooms without colliding with tables, and catch balls.
Questions addressed by the lab’s research in the expanding room include:
• Why does the brain place so much weight on the assumption that the scene remains a constant size?
• Why is the brain so willing to throw away correct information from other visual and non-visual cues?
• Can we kick the brain into using the correct cues and ignore misleading ones?
• Are judgements about different properties of the room mutually consistent?
Publications:
Svarverud, E., Gilson, S., & Glennerster, A. (2012). A Demonstration of ‘Broken’ Visual Space. PLoS ONE, 7(3): e33782. https://doi.org/10.1371/journal.pone.0033782
Svarverud, E., Gilson, S. J. and Glennerster, A. (2010). Cue combination for 3D location judgements. Journal of Vision, 10(1):5. https://doi.org/10.1167/10.1.5
Glennerster, A., Tcheang, L., Gilson, S. J., Fitzgibbon, A. W., & Parker, A. J. (2006). Humans Ignore Motion and Stereo Cues in Favor of a Fictional Stable World. Current Biology, 16(4), 428–432. https://doi.org/https://doi.org/10.1016/j.cub.2006.01.019
Rauschecker, A. M., Solomon, S. G., & Glennerster, A. (2006). Stereo and motion parallax cues in human 3D vision: Can they vanish without a trace? Journal of Vision, 6(12), 12. https://doi.org/10.1167/6.12.12
Display Calibration
We present here our calibration method for Head Mounted Displays. Unlike other calibration methods, our technique:
- Works for see-through and non-see-through HMDs.
- Fully models both the intrinsic and extrinsic properties of each HMD display.
- Support optional modelling of non-linear distortions in HMD display.
- Is a fully automated procedure, requiring only a few discrete inputs from the operator. No need to wear the HMD and make difficult judgements with a 3D stylus!
- Is quick and robust.
- Requires no separate 3D calibration.
- Delivers quantifiable results
Publications:
Scarfe, P. and Glennerster, A. (2019) The science behind virtual reality displays. Annual Review of Vision Science , 5, 529-547
Scarfe, P. and Glennerster, A. (2015) Using high-fidelity virtual reality to study perception in freely moving observers. Journal of Vision 15(9):3 1-11
Gilson, S.J. and Glennerster, A. (2012). High fidelity virtual reality. In Virtual Reality / Book 1, Dr Christiane Eichenberg (Ed.), In Tech, Rijeka, Croatia
Gilson, S. J., Fitzgibbon, A. W., & Glennerster, A. (2011). An automated calibration method for non-see-through head mounted displays. Journal of Neuroscience Methods, 199(2), 328–335. https://doi.org/10.1016/j.jneumeth.2011.05.011
Gilson, S. J., Fitzgibbon, A. W., & Glennerster, A. (2008). Spatial calibration of an optical see-through head-mounted display. Journal of Neuroscience Methods. https://doi.org/10.1016/j.jneumeth.2008.05.015
Representations
The experimental work in the group is primarily aimed at determining the type of representations that observers might build up as they move around and carry out different tasks. There is now a wiki from our lab to explore issues in this area.
A number of discursive papers from the lab discuss alternatives to 3D reconstruction as a basis for visual representation.
Videos:
Publications:
Glennerster, A. (2016) A moving observer in a 3D world. Philosophical Transactions of the Royal Society, B, 371(1697), 20150265 http://dx.doi.org/10.1098/rstb.2015.0265
Glennerster A (2015) Visual stability—what is the problem? Front. Psychol. 6:958. https://doi.org/10.3389/fpsyg.2015.00958
Glennerster, A. (2013). Representing 3D shape and location. In Dickinson, S., & Pizlo, Z. (Eds), Shape perception in human and computer vision: an interdisciplinary perspective (pp 201-212). London: Springer-Verlag 2013.
Glennerster, A., Hansard M.E., Fitzgibbon A.W. (2009) View-Based Approaches to Spatial Representation in Human Vision. In: Cremers D., Rosenhahn B., Yuille A.L., Schmidt F.R. (eds), Statistical and Geometrical Approaches to Visual Motion Analysis. Lecture Notes in Computer Science, 5604. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-03061-1_10
Glennerster, A. (2002). Computational theories of vision. Current Biology, 12(20), R682–R685. https://doi.org/10.1016/S0960-9822(02)01204-6
Glennerster, A., Hansard, M. E., & Fitzgibbon, A. W. (2001). Fixation could simplify, not complicate, the interpretation of retinal flow. Vision Research, 41(6), 815—834. https://doi.org/10.1016/s0042-6989(00)00300-x
Touch and Vision
Humans, like other animals, integrate information from multiple sensory modalities when making perceptual judgements about properties of the world. In collaboration with the Haptic Robotics group of Prof. William Harwin (School of Systems Engineering), work in the VR lab is focused on understanding how sensory information is integrated from vision and touch during interactive naturalistic tasks. To do this we use Haptic force-feedback devices in conjunction with VR to allow people to touch, pick-up and interact with 3D simulated objects.
Publications:
Adams, M., Scarfe, P., & Glennerster, A.(2015). Combining visual and proprioceptive cues to improve the discrimination of object location. Journal of Vision, 15(12):864. https://doi.org/10.1167/15.12.864
Current Projects
Past Projects
Our Publications
check out our wiki!