by Professor Guyda Armstrong, Dr Giles Bergel and Dr Rebecca Bowen
‘Envisioning Dante, c. 1472-c. 1630: Seeing and Reading the Early Printed Page’ (ENVDANTE) offers the first in-depth study of the material features of the early printed page for almost the entire corpus of prints (1472-1629) of Dante’s ‘Comedy’, using cutting-edge machine learning computational technologies and image-matching in addition to book-historical, literary and art-historical approaches. A collaboration between the universities of Manchester and Oxford, it brings together the collections of early printed books at the John Rylands library in Manchester; the Visual Geometry Group, a leading visual AI research group at Oxford; and scholars in Italian studies, book and art history in both institutions. It commenced in 2023 by digitising the Dante collection at the Rylands, by far the most comprehensive in the UK and scarcely rivalled elsewhere, including almost all extant editions from the beginning of printing in Europe. The editions range from sumptuous folios to plain-text editions for the mainstream educated readership: many of the early copies are hand-decorated: some are annotated with corrections, comments or marks of ownership and of use.
While the body of scholarship on Dante’s text is immense, as to a lesser extent is that on the illustrations, scant attention has been paid to the printed editions as an assembly of discrete elements on the page, or what we would now call ‘graphic design’. Whereas the text of the poem is consistent and uniform, printers adopted a variety of approaches to its rendition. Sometimes these were conscious choices, involving the commissioning of new artwork or commentary, or formal innovations such as the addition of indexes or title-pages. At other times, printers simply inherited stylistic conventions or physical materials such as woodblocks, or else made their best guess as to readers’ expectations and what the market would bear. A panoply of compromises, expediencies and hacks forms a vital part of all presswork, in which the text may be a given, but its setting out on the page is far from fixed.
This project aims to disentangle the conscious choices, inherited materials and forms of labour that together make up the book as printed and decorated by hand. It employs several forms of computer vision, all profoundly influenced by general developments within machine learning and related technologies over the past few decades, including several that are, revealingly, not generally considered to be ‘AI’. As important as algorithms are manual annotation and the use of Library metadata, based on decades of curatorial work in the same way as contemporary machine-learning models rely on vast pools of manual labour in training and evaluation. The project strives for transparency, and will be releasing images, metadata, annotations and downstream trained models as part of a set of outputs that will additionally include journal articles, a digital exhibition and the books themselves, digitised and enriched with the project’s own findings.
The project began with a pilot exercise in 2018 that aimed to test the potential of generic segmentation models based on deep learning for page layout analysis. These experiments continued in earnest in 2023, following the award of funding and the arrival of two postdoctoral research assistants, Rebecca Bowen and Gloria Moorman who have been working with Giles Bergel and colleagues at VGG (prominently, David Pinto, Prasanna Sridhar, Guanqi Zhang and Andrew Zisserman) to create training data and to validate the results of machine segmentation. Results so far are encouraging: the model (Mask-RCNN pretrained on COCO) has been augmented to detect such prominent (and relatively consistent) features as initial capitals, illustrations, running titles and the text of the poem itself with a good degree of accuracy. Where the model struggles (such as with irregular or small features) this may draw our attention to those page-elements that are historically unstable, or to design improvisations that are more occasional than typical. As digital humanists, we view such findings as equal to high scores for standard precision and recall evaluations.
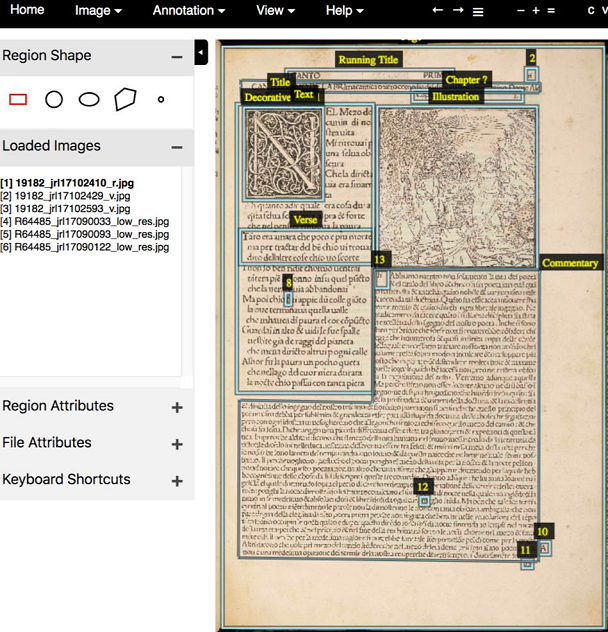
Alongside page layout analysis, the project is also performing image-matching on the books’ visual elements – their illustrations, ornaments or large initial capitals. This work package utilises VGG’s VISE software, used by several other book-historical projects, to match impressions derived from individual printing surfaces – woodblocks or metal plates: showing the industrial logic behind book production, it can reveal hidden relationships between printers renting their presses or sharing materials. We also plan to ‘collate’ copies of the same edition to uncover stop-press corrections and other copy-specific features and have already profitably experimented with VGG’s Image Compare tool.
While the digital analysis is the project’s focus, using both so-called ‘classical’ computer vision and more modern methods employing deep learning, the research directs our attention back to the books themselves, in search of the human agencies behind their production, ownership and use. By looking at books with machine vision, we hope not to replace but to enhance the human eye – AI as augmented as much as artificial intelligence.
Envisioning Dante is funded until 2025 by the Arts and Humanities Research Council (AH/W005220/1)