by Abdulrahman A. A. Alsayed
University of St Andrews, United Kingdom; King Faisal University, Saudi Arabia
Recent strides in generative AI development and the emerging abilities of pre-trained models (Wei et al., 2022) hold significant potential to automate tasks and alleviate hurdles in research workflows. Research teams can explore utilizing AI-based agents that they train to help delegate various components of the research pipeline. Developing these agents involves a process of fine-tuning a general-purpose foundation model to power them with the capability of handling specialized research tasks and to work autonomously. Such agents have proven effective in assisting with the reduction of demands in labor-intensive tasks in general, both within research contexts and beyond (Turow, 2024; Cheng et al., 2024 for an overview).

Linguistic work based on empirical studies of corpora often requires highly annotated datasets tagged with specialized linguistic information, which can prove to be labor-intensive to produce manually depending on a project’s scale. In my current project, code named CEERR (the Communicative Events Extended Reality Repository), I seek to establish a platform for documenting and analyzing the natural syntax of spoken language in modern varieties produced within immersive spatial environments. One of the aims of developing this platform is to achieve seamlessly incorporation of linguistic corpus tools, AI APIs, and virtual reality (VR) immersive experiences used as visual stimuli for speakers into one ecosystem. The project’s motivation is to enhance language documentation methods to fully capture communication environments and facilitate collaboration between speech communities and language experts in simulated virtual fieldwork settings. One of the project’s important outputs is the production of high-quality annotated datasets with audiovisual samples for low-resource language varieties that have seen little documentation work. Alsayed (2023) provides an overview of the project’s proof-of-concept and its data collection methodology.

Audiovisual corpora of spoken language and corpora of low-resource languages are especially challenging to compile into abstractable datasets. Audiovisual corpora are inherently data-rich and encapsulate textual, auditory, and visual modalities. Low-resource languages inherently lack reference corpora and dictionaries that can facilitate their annotation. Combined, creating and annotating these types of datasets can be a significant bottleneck, especially when large-scale annotation work is required. One technique I explored to alleviate the hurdle in textual annotation was fine-tuning large language models (LLMs) to tag text with linguistic annotations (Naveed et al., 2023 for an overview of fine-tuning techniques). The fine-tuning process involves prompt engineering system instructions, utilizing in-context learning, and preparing demonstration datasets tailored to the desired tasks throughout the project’s stages. The emerging classification abilities of LLMs make them excellent candidates for training as linguistic annotators of corpora through these fine-tuning techniques.
In August 2023, manual annotation work on a sample documented in the CEERR project resulted in the creation of a prototype system to assist with the automated linguistic tagging of further documented samples. The prototype features LLM functionality powered by the LangChain framework, and a graphical user interface built with the PyQt5 library. The system is built to be compatible with various LLM APIs and incorporates fine-tuning instructions and demonstration datasets customizable for different annotation needs. The system can be further configured to allow for model selection, hyperparameter adjustment, and tag set additions as required. Users can feed corpora into the system manually or through file upload, and the generated completion output is displayed through a text editor with options to export the data in multiple formats compatible with a variety of spreadsheet and corpus editing software.
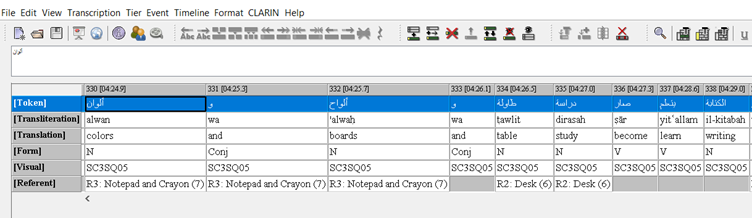
The prompts for the system instructions were engineered iteratively based on the project’s prototype corpus and initial tests of the annotation instructions. The instructions assign the task required from the agent, provide it with the desired annotation tags, and specify the output format. The instructions underwent testing with multiple LLM models and hyperparameter configurations to engineer prompts that generated satisfactory annotations. Following prompt engineering, a demonstration dataset of the desired completions was manually created to further fine-tune the LLM models through few-shot learning. Few-shot learning helps mitigate hallucination-related errors in the tagged completion. Each model’s performance after the fine-tuning process was evaluated, and the best-performing model was selected as the system’s default. A human-in-the-loop approach was also employed to manually correct the generated annotations and ensure accuracy.
On the visual side, an ongoing component of the project is exploring the use of computer vision (CV) for detecting the objects that speakers see in virtual environments. This technique is useful for determining what visual elements were part of the speaker’s immersive experiences at any given time, and time-aligning visual stimuli with speech production. This mapping of visual input and linguistic output offers a record of the spatiotemporal setting that the speaker was experiencing at each moment of speech to assist in mitigating the ephemerality of the communicative setting.
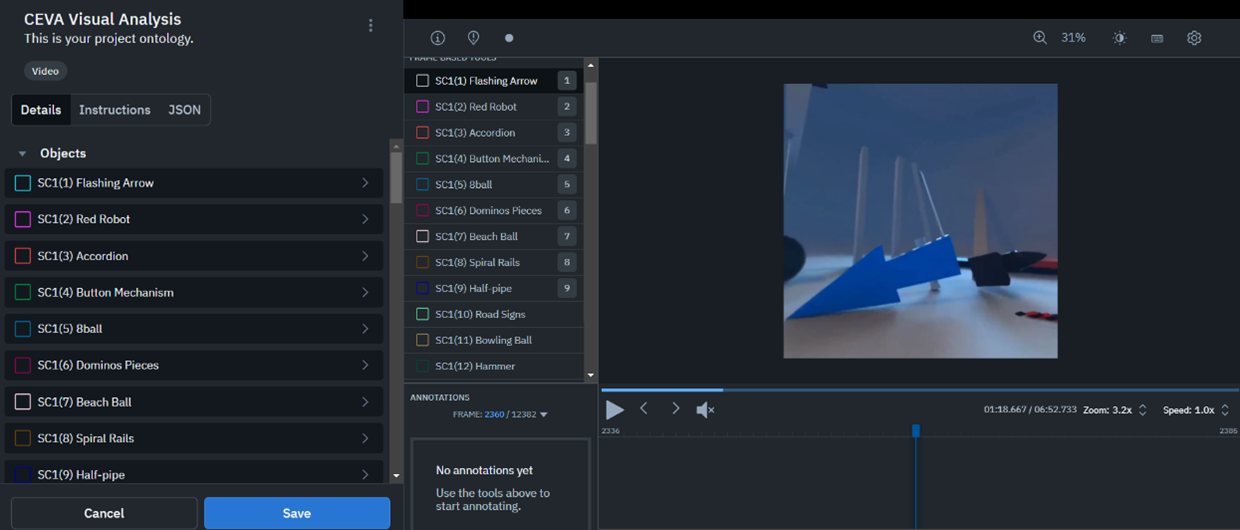
Adding annotations to the dataset informed by visual input starts with identifying all the objects contained in a stimulus virtual environment (a scene) and the actions they were involved in (a sequence). Since the environments are replicated and used across multiple speakers, utilizing CV to acquire information about the visual elements in a scene is useful to resolve the bottleneck of manually detecting these objects in the visual captures of each individual participant’s VR feed. Currently, the identified objects are used in LabelBox as terms in a custom ontology and labeled in a sample feed through a bounding box interface to be used with CV models that have custom ontology capabilities. A future step in the project is to explore how multi-agent systems can enable linguistic and visual annotator agents to work simultaneously together to provide time-aligned visual/linguistic annotations while exchanging information that aids in each agent’s tasks.
We have only started to explore the potential of integrating generative AI-based agents into linguistic research. As highlighted in this post, this integration shows promise for documenting and processing audiovisual corpora and low-resource spoken languages. This line of enquiry still holds significant potential for improving the efficiency and quality of research outputs in the field and remains largely unexplored.
Alsayed, A. A. A. (2023). Extended reality language research: Data sources, taxonomy and the documentation of embodied corpora. Modern Languages Open, Digital Modern Languages Special Collection. Liverpool University Press. https://modernlanguagesopen.org/articles/10.3828/mlo.v0i0.441 (Retrieved December 20th, 2023).
Cheng, Y., Zhang, C., Zhang, Z., Meng, X., Hong, S., Li, W., et al. (2024). Exploring large language model-based intelligent agents: Definitions, methods, and prospects. ArXiv Preprint. https://arxiv.org/abs/2401.03428 (Retrieved May 29th, 2024).
Naveed, H., Khan, A. U., Qiu, S., Saqib, M., Anwar, S., Usman, M., et al. (2023). A comprehensive overview of large language models. ArXiv Preprint. https://doi.org/10.48550/arXiv.2307.06435 (Retrieved January 15th, 2024).
Turow, J. (2024, June 5). The rise of AI agent infrastructure. Madrona. https://www.madrona.com/the-rise-of-ai-agent-infrastructure/ (Retrieved June 9th, 2024).
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., et al. (2022). Emergent abilities of large language models. ArXiv Preprint. https://doi.org/10.48550/arXiv.2206.07682 (Retrieved May 29th, 2024).