by José Pedro Sousa
Centre for Theatre Studies, University of Lisbon / Library Services, Imperial College London
Introduction
Archival research is a gateway to the past, offering invaluable insights into history, culture, and society. However, the path to accessing these treasures is often obstructed by various challenges, from ambiguous catalogue descriptions to difficulties in reading historical handwriting. While these obstacles are well documented, the focus of this discussion shifts towards the innovative solutions that are beginning to emerge, particularly in the realm of AI-driven cataloguing.




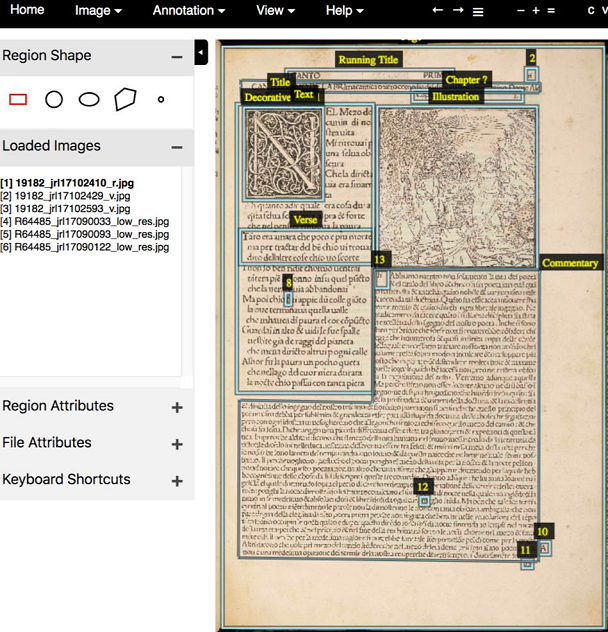
Inaccessible handwriting. Contract ref. code PT-ADLSB-NOT-CNLSB3-001-001-00113 ff. 93-94v, National Archive Torre do Tombo (Portugal)
1. Critically Embracing Technology: Transkribus and the Archives
The advancement of Handwritten Text Recognition (HTR) technology has opened new possibilities for improving access to archival records. A prime example of this is Transkribus, a tool that has gained significant attention for its ability to transcribe historical manuscripts (see Milioni 2020; Nockels et al 2022). Melissa Terras (2022), though acknowledging the benefits of the tool for libraries and archives, also forewarns for the necessity of using it critically. Terras mentions the need for 1) “ensuring a plurality of voices” (2022: 142) to be digitised and transcribed, 2) planning “how HTR can become embedded into existing digitisation and information workflows” (2022: 142) and 3) establishing standards for data handling and “openly publishing datasets” (2022: 143).
2. Methodology: Engaging Stakeholders for Effective Implementation
Integrating HTR technology into archival workflows also requires a deep understanding of the needs and concerns of those involved. To this end, I conducted fieldwork and interviews with professionals across several institutions, including university libraries, archives, and national libraries. The goal was to explore the feasibility of using HTR as a cataloguing aid and to understand how it could be effectively implemented.
The research focused on five key areas: cataloguing, collections management, digitisation, conservation, and digital archives management. Through this process, it became clear that a collaborative approach is essential. By bringing together heads of collections, archivists, cataloguers, conservators, and digitisation specialists, we can develop a workflow that not only improves efficiency but also ensures that the integrity and accessibility of archival records are maintained.
3. Workflow: A Collaborative Approach to AI-Driven Cataloguing Aid
Based on the insights gained from fieldwork and interviews, I proposed a comprehensive workflow for incorporating HTR technology into the cataloguing process. This workflow begins with the careful selection of a collection or corpus of documents to be catalogued, considering issues such as linguistic and cultural representativeness and subject matter diversity and inclusion. This selection must be followed by an assessment of the stability of the documents. Once the collection/corpus is chosen the process can begin. At this point, even physical proximity between the storage area, cataloguing office, and digitisation studio was recommended. While conducting this research, I contributed to the UCL-V&A Chinese Export Watercolour project, directed by Jin Gao, where these conditions were met, making the whole process much more agile (see Gao et al 2023).
If an item is deemed stable, it proceeds to the digitisation phase, where it is transcribed using HTR technology. If the item is unstable, it will be kept in the conservation studio to be stabilised for digitisation.
The resulting digital transcription is then used to enrich the metadata, providing additional context and facilitating easier access to the content. The use of HTR might not only accelerate cataloguing workflow but also enhances the quality of the information available to the public.
4. Outcomes: Enhancing Accessibility and Engagement
The integration of HTR technology into archival cataloguing offers several significant benefits. One of the most impactful is the improvement in accessibility. Digitised and transcribed records can be accessed by a wider audience, including people with disabilities, the elderly, and those with limited financial resources. This democratization of knowledge is a crucial step towards making archival materials more inclusive.
Moreover, the use of crowdsourcing in the transcription process can further enhance accuracy while fostering community engagement. By involving the public in the digitisation and transcription efforts, archives can attract new audiences and strengthen ties with their communities.
5. Limitations and Future Directions
While the potential of HTR technology is promising, it is not without its challenges. The current workflow relies on existing language models, which may introduce bias if not carefully managed. Future projects should consider the development of specific models tailored to diverse and inclusive collections. Additionally, the process requires a strategic allocation of human and financial resources to ensure its sustainability.
Another critical next step is the empirical evaluation of the proposed workflow. Implementing a trial period with a sample corpus will provide valuable insights into the effectiveness and efficiency of the process, allowing for adjustments and improvements before wider adoption.
Conclusion
The integration of AI-driven tools like Transkribus into archival cataloguing is a significant step forward in addressing the accessibility challenges that have long plagued researchers. By fostering collaboration among archival professionals and embracing innovative technologies, we can begin to unlock the full potential of our shared history. While there are still challenges to overcome, the path ahead is one of exciting possibilities for enhancing access to archival records and making them available to a broader, more diverse audience.

Prompt: archivist lady holding a tablet, digitisation officer, books conservator, special collections manager and Artificial Intelligence looking at an old manuscript, in a medieval archive with modern technology such as holograms, a cute and friendly robot, high tech digitisation machine
Bibliography
Gao, J., Zhang, Y., Wang, L., Li, Y., Li, F., Chang, S., Liu, J. (2023) “Unveiling the V&A Chinese Export Watercolours (CEW) Collection: A Journey of Digitisation and Discovery”. Available at: https://blogs.ucl.ac.uk/dis-blog/2023/09/08/cew/ (accessed: 9-8-2024)
Milioni, N. (2020) Automatic Transcription of Historical Documents. Transkribus as a Tool for Libraries, Archives and Scholars. MA dissertation, Uppsala Universitet. Available at: https://www.diva-portal.org/smash/get/diva2:1437985/FULLTEXT01.pdf (accessed: 9-8-2024).
Nockels, J., Gooding, P., Ames, S. and Terras, M. (2022) “Understanding the application of handwritten text recognition technology in heritage contexts: a systematic review of Transkribus in published research”, Archival Science, 22, pp. 367-392.
doi: https://doi.org/10.1007/s10502-022-09397-0 (accessed: 9-8-2024).
Terras, M. (2022) “The role of the library when computers can read: Critically adopting Handwritten Text Recognition (HTR) technologies to support research” in Wheatley, A. and Hervieux, S. (eds), The Rise of AI: Implications and Applications of Artificial Intelligence in Academic Libraries. Atlanta: ACRL – Association of College & Research Libraries, pp. 137-148. Available at: https://www.research.ed.ac.uk/en/publications/the-role-of-the-library-when-computers-can-read-critically-adopti (accessed: 9-8-2024)