New: Academic Computing Drop-in Sessions
Academic computing drop-in sessions are now run by members of our team on Wednesday afternoons! Head to our drop-in info page for details & schedule....
 Reading Academic Computing Cluster – Login and Interactive Computing
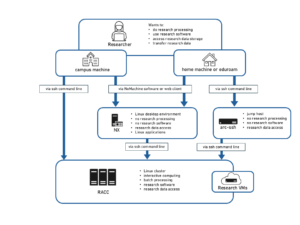
Reading Academic Computing Cluster – Login and Interactive ComputingYou can log into the Reading Academic Computing Cluster with the following command:
ssh -X USERNAME@cluster.act.rdg.ac.uk
The ‘-X’ option enables X11 forwarding, which allows the running of applications with graphical user interfaces (GUIs) such as text editors or graphics displays in data visualisation tools. See Access to ACT Servers via an SSH Client for more information and important security related recommendations.
To connect from a Windows computer you will need an SSH client such as MobaXterm. Note that there is a portable edition that does not require administrator rights to install. To connect from a Mac you will need to install XQuartz before X11 forwarding will work with the native Terminal app. If you are using Linux, including our Linux Remote Desktop Service, SSH and X11 forwarding should work without any additional configuration.
If you need to connect from an off-campus machine, the available options are described here.
From the University Wi-Fi network Eduroam, access to the UoR services is somewhere between the trusted campus wired network and untrusted off-campus network. In theory, you should be able to ssh directly to RACC when connecting from Eduroam. In practice there might be difficulties, depending on where you are on campus. In such cases you can use one of the options for connecting from outside of campus. One of the known access problems is that internal DNS is not available. In such cases using the IP address 10.210.14.253 instead of the name cluster.act.rdg.ac.uk will help.
The new cluster is now available to some users, and in the future it will fully replace RACC. You can login to RACC2 with the following command:
ssh -X USERNAME@racc.rdg.ac.uk
The above ssh command will put you on one of the RACC’s login nodes. There’s more detailed information about the layout of the cluster in the RACC introduction article, but in summary, the login nodes are your direct access points to the RACC, whereas the batch nodes run your jobs without your direct interaction.
You don’t choose the specific node that you log in to yourself. cluster.act.rdg.ac.uk (a.k.a. racc-login.act.rdg.ac.uk) acts as a load balancer and it will connect you to the least loaded login node. Both CPU load and memory use are considered in the load balancing process. Currently we have 5 login nodes with decent multicore CPUs and 386GB of memory each. They are suitable for low-intensity interactive computing, including short test runs of research code and interactive work with applications like Matlab, IDL, etc.
Please remember the fair usage policy on the RACC: The login nodes are shared among all users, so please do not oversubscribe the resources. Small jobs as outlined above are ok, but bigger jobs should be run in batch mode.
Login node sessions are limited to 12 CPU cores and 256 GB of memory per user. The CPU limit is enforced in such a way that all your processes on the node will share just 12 cores, if you run code that tries to use more than 12 more processes or threads for numerical processing, it will be inefficient, slower than using just 12 processes. Regarding the memory limit, if your processes exceed the allocation one of the processes will be killed.
If you notice that the login node becomes slow, you can try disconnecting and connecting to another node via the above ssh command which selects the least used node by load balancing. Session time limits and per process time and memory limits might be introduced in the future.
Background jobs and cronjobs are not permitted on the login nodes. If you need to run a cron job, please use our cron job node racc-cron.
After the migration in July 2018, the new Unix home directories can now provide more storage space. Also, there are now no technical reasons preventing them to be used for small scale research data processing. More storage space for research data can be purchased from the Research Data Storage Service.
The storage volumes are mounted under /storage, with some legacy paths at /storage/shared/. This includes /storage/shared/glusterfs. Some older legacy Meteorology and CINN storage volumes and mount paths are not supported on the RACC.
150 TB of free scratch space is provided at/scratch2 (Note that /scratch1 failed and it will be fixed when the lockdown is over and we regain access to the server room again).
Please note that data in scratch space is not protected and it might be periodically removed to free up space (right now periodic removals are not implemented). Scratch storage should only be used for data which you have another copy of or that can be easily reproduced (e.g. model output or downloads of large data sets). User directories will be created on request when using scratch and not other types of data storage is justified.
Software installed locally is managed by environmental modules, see our article on how to access software on the cluster for more information. The modules available on the RACC are not the same modules as those on the legacy met-cluster.
Software is compiled locally with the version of the gnu compiler suite which is installed with the RACC operating system (gcc 4.8.5). In addition to the packages built with the gnu compiler, some libraries will be also prepared for use with the Intel FORTRAN compiler.
Some scientific software packages are installed on the system from rpms, and do not require loading a module. They are available to call from command line when you log in without any extra set up.
A list of installed packages can be found here.
You can find further useful, software specific information in these articles: Python on the Academic Computing Cluster and Running Matlab Scripts as Batch Jobs.