
By Guannan Hu, May 2024
Data assimilation is a process that uses meteorological observations to improve the initial conditions for weather forecasting. To make the best use of the observations, we need to correctly specify the observation error uncertainty in the assimilation. This is because the observation error uncertainty affects the weight given to the observations in creating the initial conditions. Remote sensing observations add a layer of complexity because they can contain spatially correlated observation errors. This poses challenges not only in estimating observation error correlations [1], but also in implementing the data assimilation scheme, because the inclusion of correlated error statistics may greatly slow down computation of the assimilation process [2,3].
Why are correlated observation errors a challenge?
In data assimilation the observation error covariance matrix represents the observation error statistics. I will refer to this matrix as the R-matrix. In addition, the observation-minus-model departure vector is the difference between the observations and their model equivalents. To solve the variational minimisation problem in data assimilation, we need to compute the product of the inverse R-matrix and the observation-minus-model departure vector [2,3].
When the observation errors are uncorrelated, the R-matrix is diagonal. In this case, the inverse R-matrix is also diagonal, and its elements are the reciprocals of the elements of the R-matrix. Furthermore, the product of a diagonal inverse R-matrix with the observation-minus-model departure vector requires only floating-point operations on the order of 𝑚, where 𝑚 is the number of observations. However, for correlated observation errors the R-matrix is non-diagonal. This makes the calculation of the inverse R-matrix generally more computationally expensive. Moreover, in this case, the inverse R-matrix is typically a full matrix with elements off the diagonal not being zero. The product of the inverse R-matrix with the observation-minus-model departure vector requires on the order of 𝑚2 floating-point operations.
Parallel computing with correlated observation errors
To reduce the computational cost of the matrix-vector product, the matrix and vector elements can be stored on different processors (Figure 1). Each processor can then work on a different part of the calculation in parallel. For uncorrelated observation errors, the diagonal R-matrix means each processor can perform its tasks without exchanging information with other processors. However, for correlated observation errors, the inverse R-matrix may be a full matrix. This means the parallel computation of the matrix–vector product may require a high degree of communication between the processors. For example, with the row-wise partitioning shown in Figure. 1, each processor needs the elements of the vector stored in other processors to do its own work.
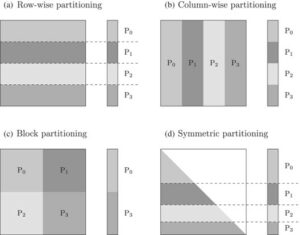
In summary, the explicit inclusion of the correlated observation error statistics allows us to make better use of high-resolution observations, such as those from geostationary satellites and Doppler radar, and thus helps to improve the accuracy of weather forecasts. However, an open challenge is how to deal with the computational issues that arise when including these statistics. In our recent studies, we investigated the use of a well-known numerical approximation method [2] and based on this we have proposed a novel approach [3]. We have shown that these approaches can reduce algorithmic complexity and communication costs by compressing the data held by each processor. There is, however, much more to be explored.
[1] Hu, G. & Dance, S.L. (2024) Sampling and misspecification errors in the estimation of observation-error covariance matrices using observation-minus-background and observation-minus-analysis statistics. Quarterly Journal of the Royal Meteorological Society, 1–26. https://doi.org/10.1002/qj.4750
[2] Hu, G. & Dance, S.L. (2021) Efficient computation of matrix–vector products with full observation weighting matrices in data assimilation. Q J R Meteorol Soc, 147(741, 4101–4121. https://doi.org/10.1002/qj.4170
[3] Hu, G., & Dance, S. L. (2024). A novel localized fast multipole method for computations with spatially correlated observation error statistics in data assimilation. Journal of Advances in Modeling Earth Systems, 16, e2023MS003871. https://doi.org/10.1029/2023MS003871





