
by Esther Conway, Alison Waterfall, Victoria Bennett
In a scientific age of ‘Big Data’, where projects are producing and analysing ever greater volumes and variety of data types, and where new infrastructures are allowing new methods of collaborative working, then good data management becomes a key ingredient in a successful research project. The complexity of the data management challenge stems not just from the volume of the data, but also from the heterogeneity of data types and sources, as well as the variety of users and uses to which the data may be put through the life of the project. This presents new challenges in the area of data management, which require the development of new methodologies to address these.
The FIDUCEO project is highly challenging in data management terms in that it anticipates that it will manage in excess of 20 complex high volume Earth Observation data sets (both input and output) that will be engaged with by multiple international partners within a collaborative high performance computing (HPC) environment. For a project such as FIDUCEO, which has scientific fidelity and traceability at its heart, then also being able to trace the provenance of any given dataset is of obvious importance. In a shared computing environment, where researchers from different institutions and countries are accessing and making use of the same data, it is important to have processes in place to record the origin and any subsequent updates to any input datasets, as well as ensuring that the final data products are archived and documented for long term posterity. Along the way, there will also be intermediate products that will have a complex lifecycle of their own and that will need tracking and archiving or removing at an appropriate stage of the research.
In order to deal with such a complex data environment a new data management structure has been created for rapidly evolving data intensive projects, and is being put into practice within FIDUCEO. The new structure honours all constituent elements of the H2020 Open Data Pilot – Data Management Plan template, but also incorporates risk management, review procedure and exposes the acquisition, archival, and preservation archival status of project data. It also encompasses other related issues such as software and website preservation, as is shown in Figure 1.
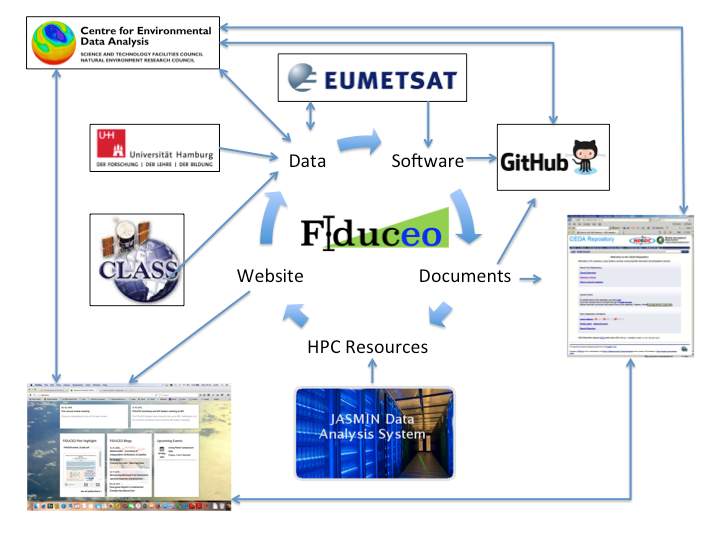
Figure 1: Data Management on the FIDUCEO Project
The data management is being done via a dedicated section of the project wiki, to allow the dynamic updating of the data management planning elements throughout the project, reflecting the evolving nature of such a complex project. Key sections in the data management plan are:
- Important information: Key data management commitments that the project must honour, and other useful data management information to support the project scientists
- Data Management: includes standards information, and individual data management plans that are integrated with the status of project data in terms of the application of standards, validation, acquisition, production, archival and/or deletion. It is important to note that all data on a project requires management and planning, not just output data sets generated by the project and selected for long term archival.
- Document management: includes information on how / where the project can deposit key documentation for long-term preservation, and a document index for key documents under active management along with their archival and approval status, association with data sets and a link to the document repository
- Software Management: includes an index containing lists of key software under active management in the FIDUCEO project along with their archival and approval status, association with datasets and links to the software repository (Git hub) along with software standards and licence information.
- Project Resources: contains key information on HPC and Archival resources available to FIDUCEO
- Governance and Review Procedures: includes details of governance and review procedure for dataset appraisal and selection for archival in addition to a data management risk register and related actions
- Website Preservation: contains a procedure for how links will be maintained between the FIDUCEO website and the long-term data archive after the project end.
In adopting the comprehensive data management structure highlighted above, FIDUCEO will ensure that both during and after the project a high quality documented data archive is created, with appropriate academic credit for the data creation, and with clearly stated conditions of use, access and deposit, preserving the rights of the data creators. For the long-term archival of the data, appropriate understanding and management of the risks to the survival of the project data will ensure that appropriate preservation strategies are employed and that scientifically valuable data can be kept for reuse in the long-term, and are visible and exploitable by the wider scientific community. Ultimately this will allow FIDUCEO to leave a lasting legacy in the data that it produces, allowing future generations of scientists to build on and extend these climate data records with new instruments and measurements extending into the future.
[cover image credit: Stephen Kill, STFC The JASMIN computing cluster is hosted by Scientific Computing Division in STFC’s Rutherford Appleton Laboratory R89 data centre on behalf of RAL Space researchers studying climate change and processing satellite data. Image taken on 20th March 2014]