By Christos Pliatsikas (Associate Professor in the School of Psychology and Clinical Language Sciences)

The fields of cognitive science and psycholinguistics are in great need of resources that can transcend cultural and linguistic barriers. This includes normative sets of images and drawings which act as standardized tools to explore language, perception, memory, and attention in diverse linguistic groups. The Multilingual Picture Database (MultiPic) is a new pioneering initiative aiming to address this gap. It comprises 500 colored object drawings with naming norms and familiarity scores across thirty-three languages and language varieties worldwide. This enables MultiPic to function as a global tool which will facilitate comparative cognitive research, accommodating a wide spectrum of cultural and linguistic backgrounds. The inclusion of a diverse range of languages, from widely spoken ones like British English and Cantonese, to less commonly studied languages, like Hungarian or Slovak, and language varieties, like Malay English or Lebanese Arabic, marks a significant step towards a more inclusive approach in cognitive and linguistic research across different linguistic and cultural groups.
For those researching multilingualism, MultiPic is an invaluable repository of data. It provides a comprehensive set of translation equivalents associated with various concepts across several languages and language varieties. To illustrate, consider the series of concepts illustrated in Figure 1 (namely, a dressing gown, a sofa, a bin and a ruler, according to their naming norms in British English). These simple and common entities are high-familiarity elements across cultures, which however do not always show reliability in their name agreement scores across different languages, but also in their actual names across different varieties of the same language (see Table 1). This highlights an important caveat in using norms of a standard language to speakers of a variety of the same language (e.g., using norms in Standard Greek with speakers of Cypriot Greek). These examples, while illustrative, highlight the potential of MultiPic in providing concrete, quantifiable data that can be used to compare and contrast cognitive processing across languages in a variety of linguistic and cultural contexts. Moreover, it is important to point out the value of such a dataset in clinical research and practice, especially for clinicians working with multilingual patients, as they can uses this tool to assess the linguistic abilities and knowledge of their patients in the different languages they speak but on the exact same items.
Figure 1. Examples of four pictorial elements from the MultiPic database.
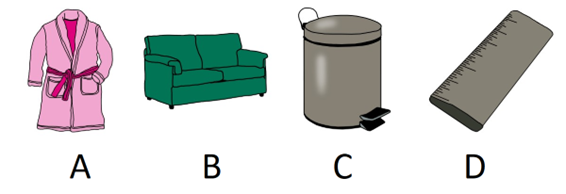
Table 1. Modal responses for each of the elements depicted in Figure 1 across languages and varieties.
| Modal responses | ||||
| Languages or Varieties | A | B | C | D |
| Arabic (Lebanese) | روب | كنبايه | زباله | مسطرة |
| Basque | bata | sofa | zakarrontzi | erregela |
| Catalan | barnús | sofà | paperera | regla |
| Chinese | ||||
| Cantonese | 浴袍 | 沙發 | 垃圾桶 | 尺 |
| Mandarin | 睡衣 | 沙发 | 垃圾桶 | 尺子 |
| Czech | župan | gauč | koš | pravítko |
| Dutch | ||||
| Standard | badjas | bank | prullenbak | liniaal |
| Flemish | badjas | zetel | vuilbak | meetlat |
| English | ||||
| American | robe | couch | trash can | ruler |
| Australian | robe | couch | bin | ruler |
| British | dressing gown | sofa | bin | ruler |
| Malay | bathrobe | sofa | bin | ruler |
| Finnish | kylpytakki | sohva | roskakori | viivotin |
| French | ||||
| Metropolitan | peignoir | canapé | poubelle | règle |
| Québécois | robe de chambre | divan | poubelle | règle |
| German | bademantel | sofa | muelleimer | lineal |
| Greek | ||||
| Standard | ρόμπα | καναπές | κάδος | χάρακας |
| Cypriot | ρόμπα | καναπές | κάλαθος | ρίγα |
| Hebrew | חלוק | ספה | פח | סרגל |
| Hungarian | köntös | kanapé | kuka | vonalzó |
| Italian | accappatoio | divano | cestino | righello |
| Korean | 가운 | 소파 | 쓰레기통 | 자 |
| Malay | baju mandi | sofa | tong sampah | pembaris |
| Norwegian | morgenkåpe | sofa | søppelbøtte | linjal |
| Polish | szlafrok | kanapa | kosz | linijka |
| Portuguese | robe | sofá | caixote de lixo | régua |
| Russian | халат | диван | мусорка | линейка |
| Serbian | bademantil | kauč | kanta | lenjir |
| Slovak | župan | gauč | kôš | pravítko |
| Spanish | ||||
| Peninsular | bata | sofá | papelera | regla |
| Rioplatense | bata | sillón | tacho | regla |
| Turkish | bornoz | koltuk | çöp kutusu | cetvel |
| Welsh | dressing gown | soffa | bin | pren mesur |
MultiPic’s impact extends beyond just being a research tool; it is a catalyst for promoting inclusivity in cognitive research. The tool supports the process of generating norms in minority and regional languages, as well as languages from the Global South; indeed, at the time of writing of this post, Multipic is being normed in languages such as Albanian, Vietnamese, Brazilian Portuguese and Galician, to name a few. This initiative not only broadens the scope of research but also brings to the forefront the linguistic and cultural richness of communities that are often underrepresented in cognitive science literature. This makes MultiPic particularly useful for researchers seeking to understand how perception and language processing may vary across different linguistic and cultural groups.
Multipic is constantly evolving: currently ongoing and future expansions are planned to include a diverse array of languages, with particular emphasis on those from lesser-represented regions. This includes minority and/or endangered languages (e.g. Maltese, Scottish Gaelic) that often lack such psycholinguistics tools, meaning that Multipic may have a role in promoting and reviving such languages, as well as the clinical and experimental work done with them. This expansion will not only enrich the dataset but also provide invaluable resources for studies that explore linguistic diversity and the nuances of language-mediated conceptualization across different cultures and communities.
Multipic is being currently used in hundreds of ongoing research actions across the world. At the same time, it remains an ongoing open-ended project, which invites interested parties to norm it in yet more languages (please get in touch if you are interested!)
The full set of norms in all published languages can accessed freely here: https://doi.org/10.6084/m9.figshare.19328939.v5